News


CHAI’s Daniel Filan Helps Teach the Next Generation of AI Researchers!
04 Sep 2018
CHAI’s Daniel Filan has spent a considerable amount of time reaching out to early career researchers and educating them on the current state of machine learning. Some of his past contributions include:

Congratulations to Anca Dragan on Her Achievements this Year
03 Sep 2018
This year, Anca Dragan has recieved the following achievements in her efforts to promote human-compatible artificial intelligence:
Anca Around the World – Conferences from the Past Year
Anca Dragan has been busy the past year, attending conferences and delivering talks everywhere from Berkeley to Switzerland to promote the safe development of AI and robotics. In the past year, she has attended a variety of events, including:

CHAI Students at Workshop on AI Alignment
26 Aug 2018
This weekend workshop brought together research interns from MIRI and UC Berkeley’s Center for Human-Compatible AI (CHAI) for the second workshop on approaches to AI alignments to discuss conceptual foundations and open problems in AI safety research.

Joseph Halpern Publishes “The Evolution of Cognitive Mechanisms in Response to Cultural Innovations”
25 Jul 2018
CHAI’s Joseph Halpern published this article in the Proceedings of the National Academy of Sciences of the United States of America (PNAS). The abstract reads:

Why is Facebook Keen on Robots? It’s Just the Future of AI
17 Jul 2018
CHAI faculty members Pieter Abbeel and Bart Selman give their thoughts on Facebook and robots. Read the article here.
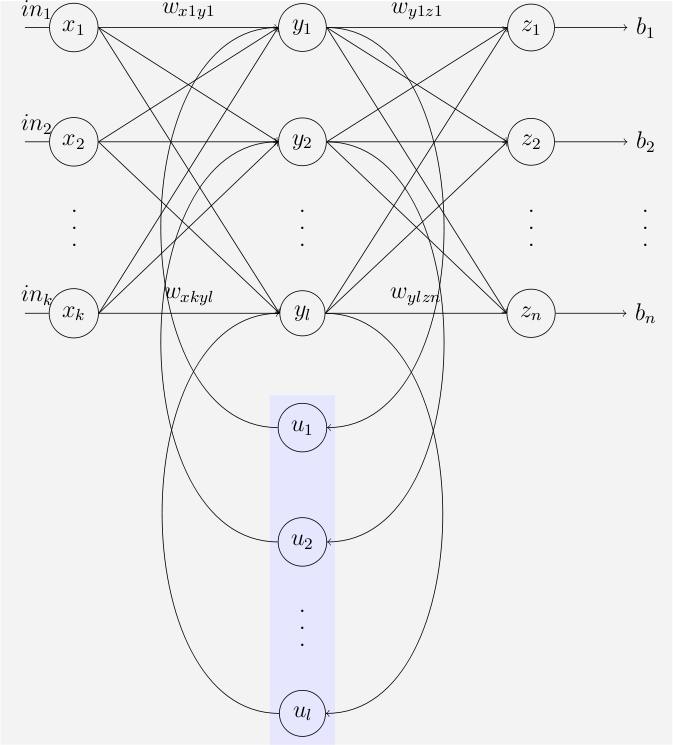
Stuart Russell and Anca Dragan Publish Paper on “An Efficient, Generalized Bellman Update For Cooperative Inverse Reinforcement Learning”
16 Jul 2018
CHAI PI Stuart Russell and co-PI Anca Dragan, with a number of other authors from Berkeley’s School of Electrical Engineering and Computer Science, published “An Efficient, Generalized Bellman Update For Cooperative Inverse Reinforcement Learning” in the Proceedings of the 35th International Conference on Machine Learning in Stockholm, Sweden back in July 2018. The paper’s abstract states that:
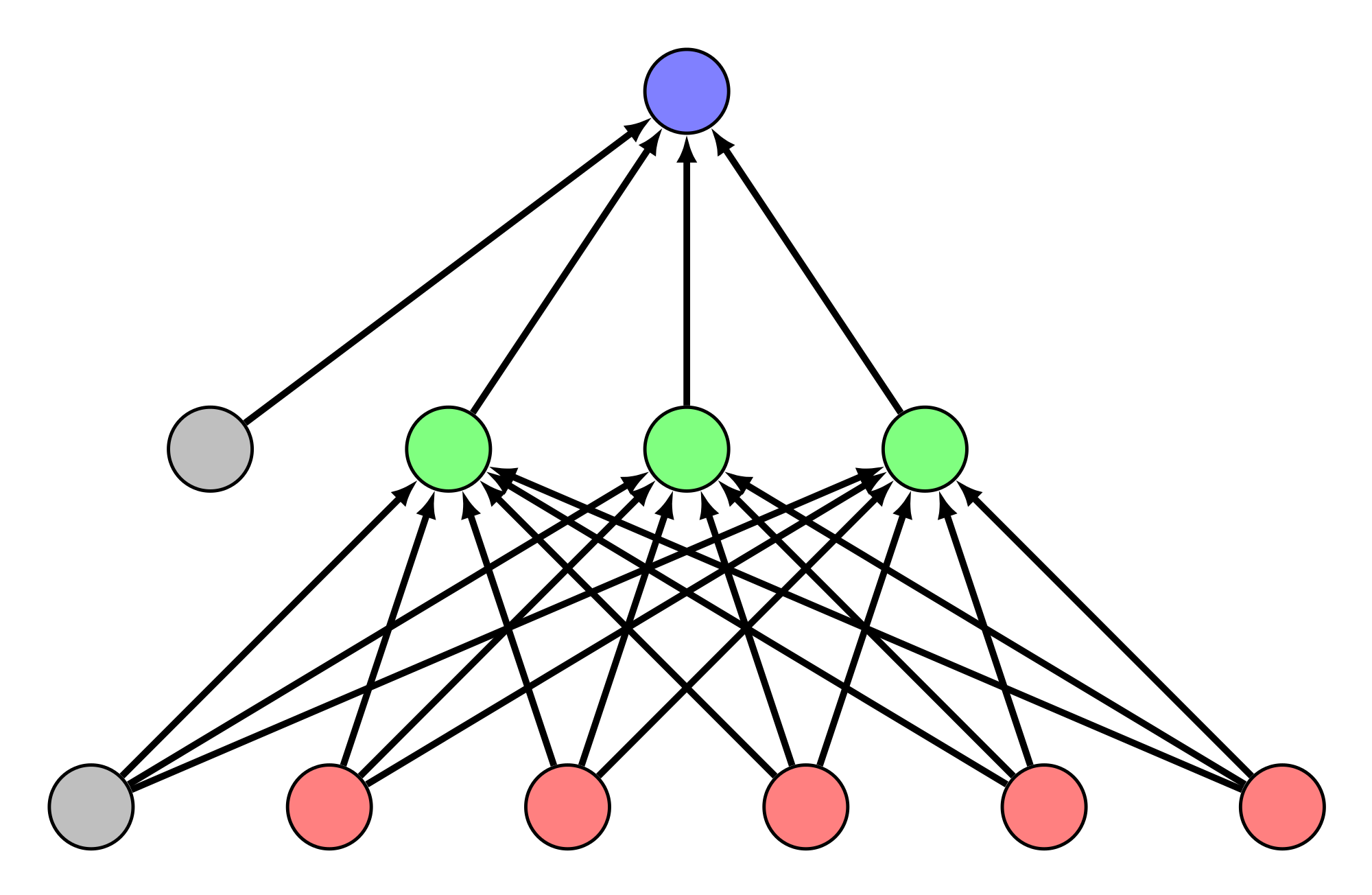
Adam Gleave Presents “Multi-task Maximum Causal Entropy Inverse Reinforcement Learning”
15 Jul 2018
CHAI’s Adam Gleave and another researcher from Berkeley published this paper in arXiv and presented at GoalsRL Workshop at FAIM. The abstract reads:
CHAI’s Adam Gleave and Rohin Shah Present “Active Inverse Reward Design”
14 Jul 2018
Two of CHAI’s researchers presented this paper at the 1st Workshop on Goal Specifications for Reinforcement Learning, FAIM 2018. The abstract reads:

Three CHAI Researchers Present at the GoalsRL Workshop
Adam Gleave and Rohin Shah attended the 2018 GoalsRL Workshop and presented the paper Active Inverse Reward Design and Adam additionally presented a paper on Multi-task Maximum Entropy Inverse Reinforcement Learning. Also, Daniel Filan presented the paper Exploring Hierarchy-Aware Inverse Reinforcement Learning.